AI Bundesliga Prognose statistisch: Datengetriebene Vorhersagen verstehen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Hinter jeder KI-Prognose für die Bundesliga steckt ein Fundament aus Zahlen. Die künstliche Intelligenz erfindet ihre Vorhersagen nicht, sie berechnet sie auf Basis statistischer Daten. Wer versteht, welche Statistiken relevant sind und wie sie verarbeitet werden, kann die Qualität von Prognosen besser einschätzen und eigene Analysen durchführen. Die Mystik des Algorithmus verschwindet, wenn man die zugrundeliegenden Prinzipien kennt.
Statistik im Fußball ist keine trockene Zahlenakrobatik, sondern ein Werkzeug zur Entscheidungsfindung. Jede Zahl erzählt eine Geschichte: Ein Ballbesitz von 65 Prozent deutet auf Dominanz hin, eine Schussgenauigkeit von 25 Prozent auf Ineffizienz, eine xG-Differenz von minus 0,8 pro Spiel auf defensive Probleme. Die Kunst liegt darin, diese Geschichten richtig zu lesen und daraus Schlüsse für kommende Spiele zu ziehen.
In diesem Artikel tauchen wir tief in die statistische Welt der Bundesliga-Prognosen ein. Wir betrachten die wichtigsten Metriken, erklären die gängigen Modelle und zeigen, wie du selbst statistische Analysen durchführen kannst. Das Ziel ist nicht, dich zum Datenanalysten zu machen, sondern dir das Verständnis zu vermitteln, das für informierte Wettentscheidungen notwendig ist.
Die wichtigsten Statistiken für Fußballprognosen
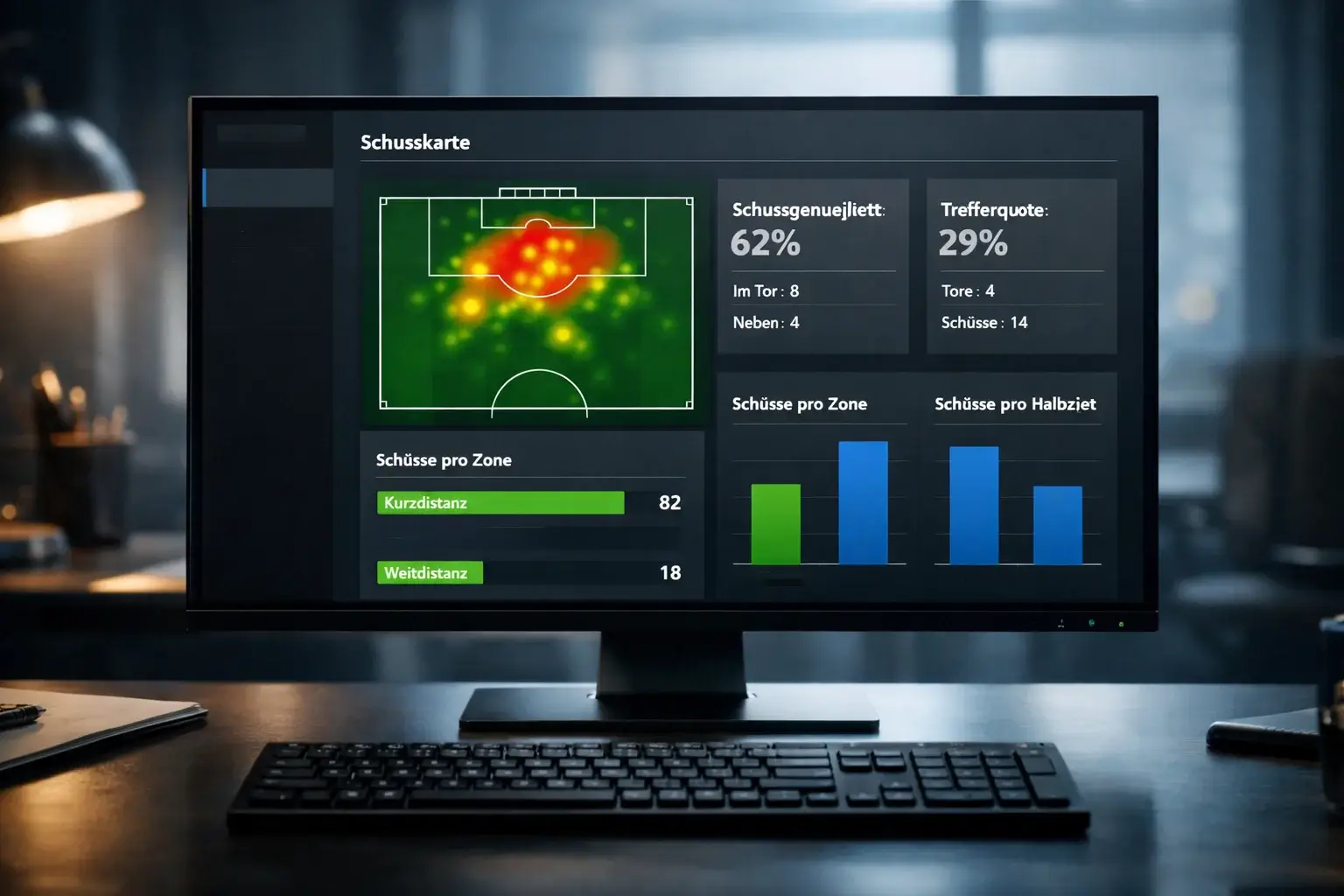
Tore und Gegentore als Basismetriken
Die grundlegendste Statistik im Fußball sind Tore, geschossene wie kassierte. Sie bestimmen direkt das Ergebnis und sind der ultimative Maßstab für Erfolg. Für Prognosen sind nicht die absoluten Zahlen entscheidend, sondern die Durchschnitte und Trends. Ein Team, das in den letzten zehn Spielen im Schnitt 2,1 Tore geschossen und 0,9 kassiert hat, bringt andere Voraussetzungen mit als eines mit 1,2 geschossenen und 1,8 kassierten Toren.
Die Tordifferenz ist ein schneller Indikator für die Gesamtstärke eines Teams. Positive Differenz bedeutet mehr geschossene als kassierte Tore, was langfristig mit Erfolg korreliert. Die Bundesliga-Tabelle basiert zwar auf Punkten, aber die Tordifferenz als Tiebreaker zeigt ihre Bedeutung. Teams mit hoher positiver Differenz sind tendenziell besser als solche mit gleicher Punktzahl, aber niedrigerer Differenz.
Die Aufteilung in Heim- und Auswärtstore liefert zusätzliche Einblicke. Manche Teams sind zu Hause Tormaschinen und auswärts harmlos. Andere zeigen keine großen Unterschiede zwischen Heim und Auswärts. Diese Muster sind relevant für Spielprognosen: Wenn das Heimteam zu Hause stark trifft und das Auswärtsteam defensiv instabil ist, erhöht das die erwartete Torzahl.
Schussstatistiken und Effizienz
Tore entstehen aus Torschüssen, und die Analyse der Schüsse liefert tiefere Einblicke als die reinen Torergebnisse. Die Anzahl der Schüsse zeigt, wie viele Abschlüsse ein Team generiert. Die Qualität der Schüsse, gemessen etwa durch xG, zeigt, wie gefährlich diese Abschlüsse sind. Die Schussgenauigkeit, also der Anteil der Schüsse aufs Tor, zeigt die technische Präzision.
Ein Team mit vielen Schüssen, aber niedriger Schussgenauigkeit verschwendet Chancen. Ein Team mit wenigen, aber präzisen Schüssen arbeitet effizienter. Für Prognosen ist die Kombination aus Quantität und Qualität entscheidend. Das optimale Team generiert viele Chancen und verwertet sie gut, aber solche Teams sind selten und stehen meist oben in der Tabelle.
Die Blockstatistiken ergänzen das Bild. Wie viele Schüsse des Gegners werden geblockt, bevor sie den Torwart erreichen? Ein Team mit hoher Blockquote hat eine aktive, aggressive Defensive. Ein Team, das wenig blockt, lässt den Gegner ungehindert schießen. Diese Unterschiede beeinflussen die erwarteten Gegentore und damit die Prognose.
Ballbesitz und Passquote
Ballbesitz ist eine der meistdiskutierten Statistiken im modernen Fußball. Hoher Ballbesitz bedeutet Kontrolle über das Spiel, aber nicht automatisch Erfolg. Manche Teams mit über 60 Prozent Ballbesitz verlieren regelmäßig, während effektive Konterteams mit 40 Prozent Erfolge feiern. Die Interpretation des Ballbesitzes erfordert Kontext.
Die Passquote, also der Anteil erfolgreicher Pässe an der Gesamtzahl, korreliert mit dem Ballbesitz. Teams mit hoher Passquote behalten den Ball länger. Interessanter ist die Passquote im letzten Drittel des Spielfelds, also in der Nähe des gegnerischen Tors. Dort ist erfolgreiches Passspiel schwieriger, weil der Gegner dichter steht. Eine hohe Quote im letzten Drittel deutet auf Qualität im Offensivspiel hin.
Die Progression, also wie effektiv ein Team den Ball nach vorne bringt, ist eine weitere relevante Metrik. Sie misst, wie viele Pässe ins letzte Drittel gelingen und wie viele Ballführungen dort enden. Teams mit guter Progression kontrollieren nicht nur das Spiel, sondern tragen es auch zum gegnerischen Tor.
Defensive Metriken verstehen
Die Defensive lässt sich durch verschiedene Statistiken charakterisieren. Die offensichtlichste ist die Anzahl der kassierten Tore, aber diese allein sagt wenig über die Qualität der Abwehrarbeit aus. Glückliche Pfostentreffern oder überragende Torwartleistungen können schwache Defensiven kaschieren.
Das Expected Goals Against (xGA) misst die Qualität der zugelassenen Chancen. Ein niedriges xGA bedeutet, dass die Defensive den Gegner zu schwierigen Abschlüssen zwingt. Ein hohes xGA deutet auf Lücken hin, die gefährliche Torchancen ermöglichen. Die Differenz zwischen xGA und tatsächlich kassierten Toren zeigt, ob der Torwart über oder unter Erwartung performt.
Weitere defensive Metriken umfassen Zweikampfquoten, Abfangaktionen und Klärungen. Ein Team mit hoher Zweikampfquote gewinnt viele Duelle und stört den gegnerischen Spielaufbau. Viele Abfangaktionen deuten auf gutes Stellungsspiel und Antizipation hin. Diese Detailstatistiken helfen, die Art der Defensive zu charakterisieren: aggressiv oder abwartend, hoch pressend oder tief verteidigend.
Set-Piece-Statistiken als Spezialbereich
Standardsituationen, also Ecken, Freistöße und Einwürfe, sind ein eigener Analysebereich. Etwa ein Drittel aller Bundesliga-Tore fallen nach Standards. Teams mit starkem Set-Piece-Spiel haben einen strukturellen Vorteil, der in Prognosen berücksichtigt werden sollte.
Die Gefährlichkeit bei Ecken lässt sich durch xG pro Ecke messen. Teams mit hohem Wert kreieren aus Ecken gute Chancen, sei es durch gut eingespielte Varianten oder einfach durch physische Stärke in der Luft. Teams mit niedrigem Wert verschwenden ihre Ecken weitgehend wirkungslos.
Freistöße nahe des Strafraums sind besonders wertvoll. Ein Team mit einem Spezialisten für direkte Freistoßtore hat einen Vorteil, der in der Gesamtstatistik nicht immer sichtbar ist. Die Analyse individueller Stärken bei Standards ergänzt die teamweiten Metriken.
Statistische Modelle in der Praxis
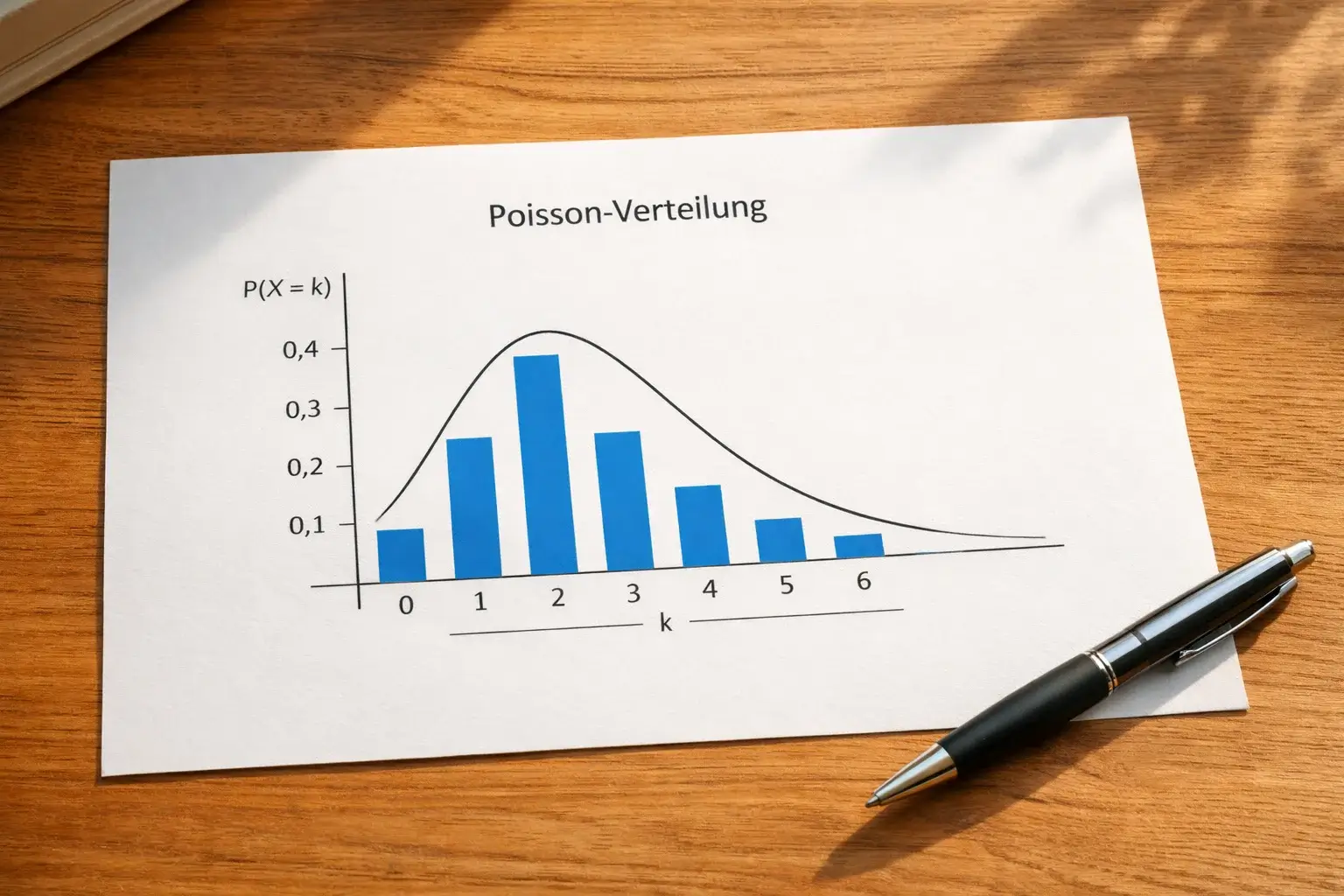
Die Poisson-Verteilung für Torprognosen
Die Poisson-Verteilung ist das mathematische Fundament vieler Fußball-Prognosemodelle. Sie beschreibt die Wahrscheinlichkeit für eine bestimmte Anzahl von Ereignissen in einem festen Zeitraum, wenn diese Ereignisse unabhängig voneinander und mit konstanter Rate auftreten. Tore im Fußball erfüllen diese Bedingungen annähernd.
Die Anwendung ist elegant: Wenn ein Team im Schnitt 1,5 Tore pro Spiel schießt, berechnet die Poisson-Verteilung die Wahrscheinlichkeiten für null, eins, zwei, drei oder mehr Tore. Die Wahrscheinlichkeit für genau ein Tor liegt dann bei etwa 33 Prozent, für zwei Tore bei etwa 25 Prozent, für null Tore bei etwa 22 Prozent. Diese Wahrscheinlichkeiten sind das Rohmaterial für Ergebnisprognosen.
Die Kombination der Poisson-Verteilungen beider Teams ergibt eine vollständige Ergebnismatrix. Für jede mögliche Torkombination, 0:0, 1:0, 0:1, 1:1, 2:0 und so weiter, lässt sich eine Wahrscheinlichkeit berechnen. Die Summe aller Heimsieg-Ergebnisse ergibt die Heimsieg-Wahrscheinlichkeit, analog für Unentschieden und Auswärtssieg.
Elo-Ratings für Spielstärke
Das Elo-System stammt ursprünglich aus dem Schach und wurde für den Fußball adaptiert. Es weist jedem Team einen Zahlenwert zu, der die Spielstärke repräsentiert. Nach jedem Spiel werden die Werte angepasst: Der Sieger gewinnt Punkte, der Verlierer verliert welche. Die Höhe der Anpassung hängt vom erwarteten versus tatsächlichen Ergebnis ab.
Der Vorteil von Elo-Ratings liegt in ihrer Einfachheit und Interpretierbarkeit. Ein Team mit einem Elo-Rating von 1800 ist stärker als eines mit 1600. Der Unterschied lässt sich direkt in Siegwahrscheinlichkeiten umrechnen. Etwa 100 Elo-Punkte Unterschied entsprechen einer Siegwahrscheinlichkeit von etwa 64 Prozent für das stärkere Team.
Für die Bundesliga existieren verschiedene Elo-Ratings von unterschiedlichen Anbietern. Die bekanntesten stammen von FiveThirtyEight, das globale Klubfußball-Ratings pflegt. Diese Ratings berücksichtigen nicht nur Ergebnisse, sondern auch Torverhältnisse und passen sich nach jeder Partie an.
Regressionsmodelle für komplexe Zusammenhänge
Während Poisson und Elo relativ einfache Modelle sind, nutzen fortgeschrittene KI-Systeme Regressionsmodelle, die viele Variablen gleichzeitig verarbeiten. Eine multiple Regression kann den Einfluss von xG, Ballbesitz, Forumkurve, Verletzungen und Dutzenden weiterer Faktoren auf das Spielergebnis schätzen.
Das Prinzip ist die Identifikation von Zusammenhängen in historischen Daten. Wenn Teams mit hohem xG und kurzer Anreise in der Vergangenheit besser abschnitten, lernt das Modell diesen Zusammenhang und wendet ihn auf zukünftige Spiele an. Je mehr Daten verfügbar sind, desto präziser werden die Schätzungen.
Die Gefahr bei komplexen Modellen ist das Overfitting. Ein Modell, das perfekt zu den historischen Daten passt, kann bei neuen Daten versagen, weil es Zufallsmuster statt echter Zusammenhänge gelernt hat. Gute Prognosemodelle balancieren Komplexität und Robustheit, indem sie auf Cross-Validation und Out-of-Sample-Tests setzen.
Korrelation vs. Kausalität
Typische Fehlinterpretationen vermeiden
Ein fundamentaler Fehler in der statistischen Analyse ist die Verwechslung von Korrelation und Kausalität. Zwei Variablen können zusammenhängen, ohne dass eine die andere verursacht. Hoher Ballbesitz korreliert mit Erfolg, aber mehr Ballbesitz führt nicht automatisch zu mehr Siegen. Erfolgreiche Teams haben oft viel Ballbesitz, weil der Gegner hinterherlaufen muss, nicht umgekehrt.
Ein klassisches Beispiel ist der Zusammenhang zwischen Fouls und Niederlagen. Teams, die viel foulen, verlieren häufiger. Daraus zu schließen, dass weniger Fouls zu mehr Siegen führen, wäre falsch. Wahrscheinlicher ist, dass Teams in Rückstand mehr foulen, weil sie verzweifelt versuchen, das Spiel zu drehen. Die Kausalität verläuft von der Niederlage zum Foul, nicht umgekehrt.
Für Prognosen ist diese Unterscheidung kritisch. Ein Modell, das auf Scheinkorrelationen basiert, wird scheitern. Die Identifikation echter kausaler Zusammenhänge erfordert theoretisches Verständnis des Spiels und sorgfältige statistische Analyse. Nicht alles, was korreliert, ist auch prognostisch relevant.
Welche Statistiken wirklich vorhersagen
Empirische Studien haben untersucht, welche Statistiken die beste Vorhersagekraft für zukünftige Ergebnisse haben. Die Ergebnisse sind teilweise überraschend. Tordifferenz und xG-Differenz sind starke Prädiktoren, während Ballbesitz allein wenig Vorhersagekraft hat. Schussstatistiken sind relevant, aber weniger als oft angenommen.
Die Stabilität einer Statistik über Zeit ist ein Indikator für ihre Vorhersagekraft. Wenn ein Team in der ersten Saisonhälfte hohe xG-Werte hatte, wird es diese in der zweiten Hälfte wahrscheinlich beibehalten. Wenn es hingegen eine hohe Schussumwandlungsrate hatte, ist diese weniger stabil und tendiert zur Regression. Stabile Metriken sind für Prognosen wertvoller.
Die Kombination mehrerer Statistiken liefert bessere Vorhersagen als jede einzelne. Ein Modell, das nur xG verwendet, ist weniger präzise als eines, das xG, Elo-Rating und Formkurve kombiniert. Die Kunst liegt in der richtigen Gewichtung und der Vermeidung von Redundanz zwischen den Variablen.
Bundesliga-spezifische Statistiken

Der Heimvorteil in der Bundesliga
Der Heimvorteil ist ein etabliertes Phänomen im Fußball, aber seine Ausprägung variiert zwischen Ligen. In der Bundesliga gewinnt das Heimteam etwa 45 Prozent der Spiele, verglichen mit etwa 27 Prozent Auswärtssiegen und 28 Prozent Unentschieden. Diese Verteilung ist stabiler als oft angenommen, mit nur geringen Schwankungen zwischen den Saisons.
Die Gründe für den Heimvorteil sind vielfältig: vertraute Umgebung, keine Anreiseermüdung, Unterstützung der Fans, Kenntnis des Platzes. Interessanterweise sank der Heimvorteil während der Geisterspiele in der Corona-Zeit, was die Bedeutung der Fans unterstreicht. Nach Rückkehr der Zuschauer normalisierte sich der Effekt wieder.
Für Prognosen muss der Heimvorteil quantifiziert werden. Eine gängige Methode ist die Anpassung der erwarteten Tore: Das Heimteam erhält einen Bonus von etwa 0,3 bis 0,4 Toren auf seine erwartete Torquote. Diese Adjustierung fließt in die Poisson-Berechnung ein und beeinflusst die Ergebniswahrscheinlichkeiten entsprechend.
Torstatistiken im Ligavergleich
Die Bundesliga ist historisch eine der torreichsten großen Ligen. Mit etwa 3,1 Toren pro Spiel liegt sie über der Serie A, Ligue 1 und oft auch der Premier League. Dieser Unterschied beeinflusst die Kalibrierung von Prognosemodellen. Ein Modell, das auf Premier-League-Daten trainiert wurde, unterschätzt möglicherweise die Torquote in der Bundesliga.
Die höhere Torquote hat verschiedene Ursachen. Der offensive Spielstil vieler Bundesliga-Teams, die Intensität des Pressings und die taktische Ausrichtung auf Tempofußball tragen dazu bei. Auch die Qualitätsdifferenz zwischen Spitze und Keller ist in der Bundesliga deutlich, was zu vielen klaren Siegen führt.
Für Over/Under-Wetten ist die Liga-spezifische Torquote entscheidend. Eine Over-2.5-Quote, die auf einem Ligadurchschnitt von 2,7 Toren basiert, bietet anderen Value als eine, die 3,1 Tore zugrunde legt. Die Kenntnis der Bundesliga-Spezifika verbessert die Prognosequalität.
Saisonale Muster erkennen
Die Bundesliga folgt saisonalen Rhythmen, die in Prognosen berücksichtigt werden sollten. Die ersten Spieltage sind unberechenbarer, weil neue Spieler und Trainer sich noch einfinden müssen. Die historischen Daten bilden die aktuelle Situation noch nicht ab, was die Prognosequalität mindert.
Die Winterpause ist ein Bruchpunkt. Transfers und taktische Umstellungen können die Machtverhältnisse verschieben. Ein Team, das in der Hinrunde dominierte, kann in der Rückrunde einbrechen, und umgekehrt. Die Prognosen müssen diese Diskontinuität berücksichtigen und nach der Pause vorsichtiger sein.
Die letzten Spieltage zeigen Motivationseffekte. Teams ohne Ziele spielen anders als solche im Abstiegskampf oder mit Meisterchancen. Diese psychologischen Faktoren sind statistisch schwer zu fassen, beeinflussen aber die Ergebnisse. Fortgeschrittene Modelle versuchen, Motivation zu quantifizieren, etwa durch die Analyse historischer Daten zu ähnlichen Tabellenkonstellationen.
Statistische Analyse selbst durchführen

Tools und Datenquellen für Einsteiger
Wer eigene statistische Analysen durchführen möchte, braucht Daten und Werkzeuge. Für Daten bieten sich kostenlose Quellen wie FBref, Understat oder Transfermarkt an. Diese Plattformen stellen umfangreiche Statistiken bereit, die für grundlegende Analysen ausreichen.
Als Werkzeug genügt für den Einstieg eine Tabellenkalkulation wie Excel oder Google Sheets. Damit lassen sich Daten organisieren, Durchschnitte berechnen und einfache Visualisierungen erstellen. Wer tiefer einsteigen möchte, kann mit Python oder R arbeiten, Programmiersprachen mit starken Statistik-Bibliotheken.
Konkrete Ressourcen zum Lernen finden sich in Blogs und Online-Kursen zur Fußball-Analytik. Die Community ist aktiv und teilt Wissen großzügig. Twitter, oder wie es heute heißt, und spezialisierte Foren bieten Austauschmöglichkeiten mit anderen Analysten.
Schritt-für-Schritt zur ersten eigenen Analyse
Ein einfaches Projekt für den Einstieg ist die Erstellung einer Poisson-Prognose für ein Bundesliga-Spiel. Zunächst sammelst du die Torergebnisse beider Teams der letzten zehn Spiele. Berechne den Durchschnitt der geschossenen und kassierten Tore jeweils für Heim- und Auswärtsspiele.
Dann adjustierst du für den Heimvorteil. Addiere 0,35 Tore zur Heimmannschafts-Erwartung und subtrahiere 0,35 von der Auswärtsmannschafts-Erwartung. Diese Adjustierung ist grob, aber ein vernünftiger Startpunkt.
Mit diesen erwarteten Torwerten berechnest du die Poisson-Wahrscheinlichkeiten. In Excel gibt die Funktion POISSON.VERT die Wahrscheinlichkeit für eine bestimmte Torzahl bei gegebenem Erwartungswert. Multipliziere die Einzelwahrscheinlichkeiten beider Teams für jede Ergebniskombination und summiere zu den 1X2-Wahrscheinlichkeiten auf.
Validierung und Verbesserung
Deine erste Analyse wird nicht perfekt sein, aber das ist in Ordnung. Der Lerneffekt liegt im Prozess. Vergleiche deine Prognosen mit den tatsächlichen Ergebnissen über mehrere Spieltage. Wo lagst du daneben? Welche Faktoren hast du übersehen?
Die schrittweise Verbesserung ist der Schlüssel. Füge xG-Daten hinzu, um die Torerwartung präziser zu schätzen. Berücksichtige die Formkurve, indem du neuere Spiele stärker gewichtest. Integriere Verletzungsinformationen, um Kaderqualität einzuschätzen. Jede Erweiterung sollte die Prognosequalität verbessern, was du durch Backtesting überprüfen kannst.
Das Ziel ist nicht, die besten KI-Systeme zu übertreffen, sondern das Verständnis zu entwickeln, das für informierte Nutzung von Prognosen notwendig ist. Wer einmal selbst ein Modell gebaut hat, versteht die Stärken und Schwächen aller Prognosen besser.
Häufige Fehler bei statistischen Analysen

Überanpassung an historische Daten
Ein verbreiteter Fehler ist die Überanpassung des Modells an vergangene Daten. Wenn du ein Modell baust, das die letzten zwanzig Spieltage perfekt erklärt, beweist das noch nicht, dass es zukünftige Spiele gut vorhersagt. Das Modell könnte Zufallsmuster gelernt haben, die sich nicht wiederholen werden.
Die Lösung ist die Trennung von Trainings- und Testdaten. Baue dein Modell nur auf einem Teil der Daten auf und teste es dann auf dem Rest. Wenn die Performance auf den Testdaten deutlich schlechter ist als auf den Trainingsdaten, liegt Überanpassung vor. In diesem Fall solltest du das Modell vereinfachen.
Cross-Validation ist eine fortgeschrittene Technik, die dieses Prinzip systematisiert. Die Daten werden mehrfach in verschiedene Trainings- und Testsets aufgeteilt, und die durchschnittliche Performance gibt ein robustes Bild der Prognosequalität.
Vernachlässigung der Stichprobengröße
Statistische Schlüsse erfordern ausreichend große Stichproben. Wenn ein Team drei Spiele hintereinander zu null gewonnen hat, ist das beeindruckend, aber statistisch nicht aussagekräftig. Drei Spiele sind zu wenige, um robuste Schlüsse über die Defensivqualität zu ziehen. Die Varianz ist zu hoch.
Als Faustregel sind mindestens zehn bis zwanzig Datenpunkte nötig, um Trends zu erkennen. Für präzise Schätzungen braucht es noch mehr. Die komplette Vorsaison mit 34 Spielen liefert solide Daten, aber selbst das reicht nicht für alle Analysen aus. Manche Muster zeigen sich erst über mehrere Saisons.
Die Konsequenz für die Praxis: Sei vorsichtig mit Schlüssen aus kleinen Stichproben. Kurzfristige Trends können Zufall sein. Langfristige Muster sind verlässlicher, aber möglicherweise veraltet, wenn sich die Umstände geändert haben.
Ignorieren von Kontextfaktoren
Reine Statistik ohne Kontextwissen kann in die Irre führen. Ein Team mit schwachen Zahlen könnte verletzt gewesen sein, gegen Top-Gegner gespielt haben oder einen Trainerwechsel durchgemacht haben. Diese Kontextfaktoren erklären die Zahlen und sollten in die Interpretation einfließen.
Die Integration von Kontext erfordert Fußballwissen jenseits der Statistik. Wer die Bundesliga verfolgt, weiß, welche Teams gerade in einer Krise stecken, welche Trainer unter Druck stehen und welche Neuzugänge sich eingelebt haben. Dieses qualitative Wissen ergänzt die quantitative Analyse.
Das beste Vorgehen kombiniert beide Perspektiven: Beginne mit den Zahlen, um eine objektive Grundlage zu haben, und ergänze dann das Kontextwissen, um die Zahlen zu interpretieren und Anpassungen vorzunehmen.
Fortgeschrittene statistische Konzepte
Bayesianische Methoden
Bayesianische Statistik bietet einen alternativen Rahmen für Prognosen. Statt einer einzelnen Schätzung liefert sie eine Wahrscheinlichkeitsverteilung über mögliche Werte. Diese Verteilung wird kontinuierlich aktualisiert, wenn neue Daten eintreffen. Der Ansatz ist natürlich für Fußballprognosen, wo Unsicherheit allgegenwärtig ist.
Die praktische Anwendung nutzt Prior-Wissen, also Vorwissen vor dem Spiel, und aktualisiert es mit den Daten. Wenn du vor der Saison davon ausgehst, dass ein Aufsteiger etwa 1,0 Tore pro Spiel schießen wird, und die ersten fünf Spiele zeigen 1,4 Tore pro Spiel, verschiebt sich deine Schätzung nach oben, aber nicht vollständig auf 1,4, weil du dein Vorwissen einbeziehst.
Dieser Ansatz ist robuster gegenüber kleinen Stichproben als rein frequentistische Methoden. Er erfordert allerdings die Spezifikation des Prior-Wissens, was subjektiv sein kann. Die Balance zwischen Prior und Daten ist eine Kunst, die Erfahrung erfordert.
Machine Learning im Überblick
Machine Learning geht über klassische Statistik hinaus und nutzt Algorithmen, die Muster in Daten selbst finden. Neuronale Netze, Random Forests und Gradient Boosting sind Beispiele für Methoden, die in fortgeschrittenen Fußball-Prognosen zum Einsatz kommen.
Diese Methoden können komplexe Zusammenhänge erfassen, die lineare Modelle übersehen. Ein neuronales Netz könnte lernen, dass ein bestimmtes Kombinationsmuster aus Ballbesitz, Pressing-Intensität und Torschützenstärke besonders erfolgreich ist, ohne dass der Analyst diesen Zusammenhang explizit spezifizieren muss.
Die Kehrseite ist die Blackbox-Natur vieler ML-Modelle. Sie liefern Vorhersagen, aber erklären nicht, warum. Für den praktischen Einsatz ist das oft akzeptabel, solange die Vorhersagen genau sind. Für das Verständnis und die Weiterentwicklung ist Interpretierbarkeit aber wertvoll.
Zusammenfassung und Ausblick
Statistik ist das Fundament jeder seriösen Bundesliga-Prognose. Die KI verarbeitet Daten zu Toren, Schüssen, Ballbesitz und Dutzenden weiteren Metriken, um Wahrscheinlichkeiten zu berechnen. Das Verständnis dieser Grundlagen ermöglicht eine kritische Einschätzung von Prognosen und den Einstieg in eigene Analysen.
Die wichtigsten Erkenntnisse: Nicht alle Statistiken sind gleich relevant. xG und Tordifferenz sind starke Prädiktoren, Ballbesitz allein weniger. Korrelation ist nicht Kausalität, und komplexe Modelle können an Overfitting scheitern. Die Bundesliga hat spezifische Charakteristiken, die in Prognosen berücksichtigt werden müssen.
Für die praktische Anwendung empfiehlt sich ein schrittweiser Ansatz. Beginne mit den Grundlagen, verstehe die gängigen Modelle, und vertiefe dich dann in die Details. Die Kombination aus statistischem Verständnis und Fußballwissen liefert bessere Einschätzungen als jeder Ansatz allein.